
[DS]Data Preprocessing - UnderSampling and OverSampling
Published in , 2024
This time we will look at the basic concepts of UnderSampling and OverSampling.
Concepts of UnderSampling and OverSampling
In reality, the result of collecting a lot of data often has an imbalanced distribution. In such cases, it can cause a decrease in accuracy when training the model. From this awareness of the problem, methods such as UnderSampling and OverSampling have emerged. 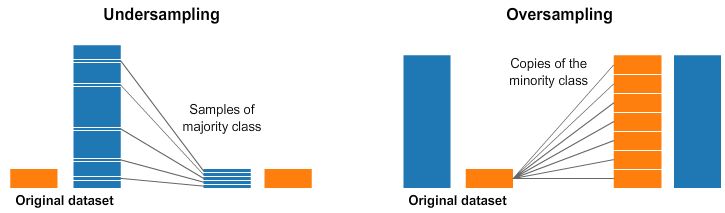
Source: https://www.kaggle.com/code/rafjaa/resampling-strategies-for-imbalanced-datasets
UnderSampling reduces the number of data in the class that occupies a high proportion, and OverSampling increases the data of the class with a low proportion. It should be noted that UnderSampling can reduce the data and lower the performance of the model.
Methods of UnderSampling and OverSampling
To look at it more practically, I referred to the sklearn documentation. The images were also taken from this site.
https://imbalanced-learn.org/stable/under_sampling.html
UnderSampling Methods
(1) Prototype Generation Prototype generation creates representative samples (prototypes) that summarize the data of the majority class, reducing the overall data while maintaining important characteristics of the original data. 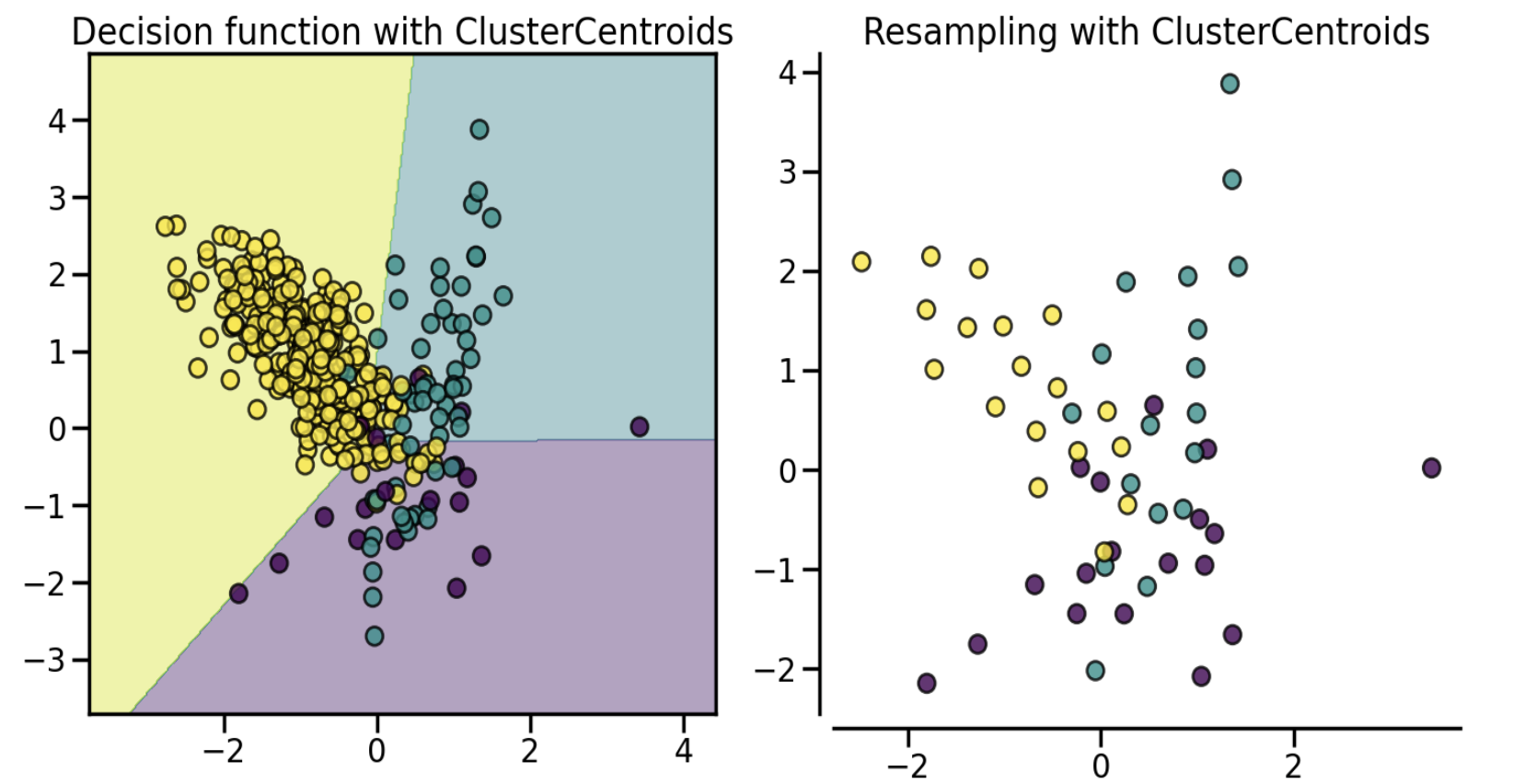
(2) Prototype Selection Prototype Selection is a technique that selects only important samples from the data of the majority class to solve the problem of imbalanced data. A typical example is RandomUnderSampler. It reduces the number of data by randomly selecting data from the majority class. 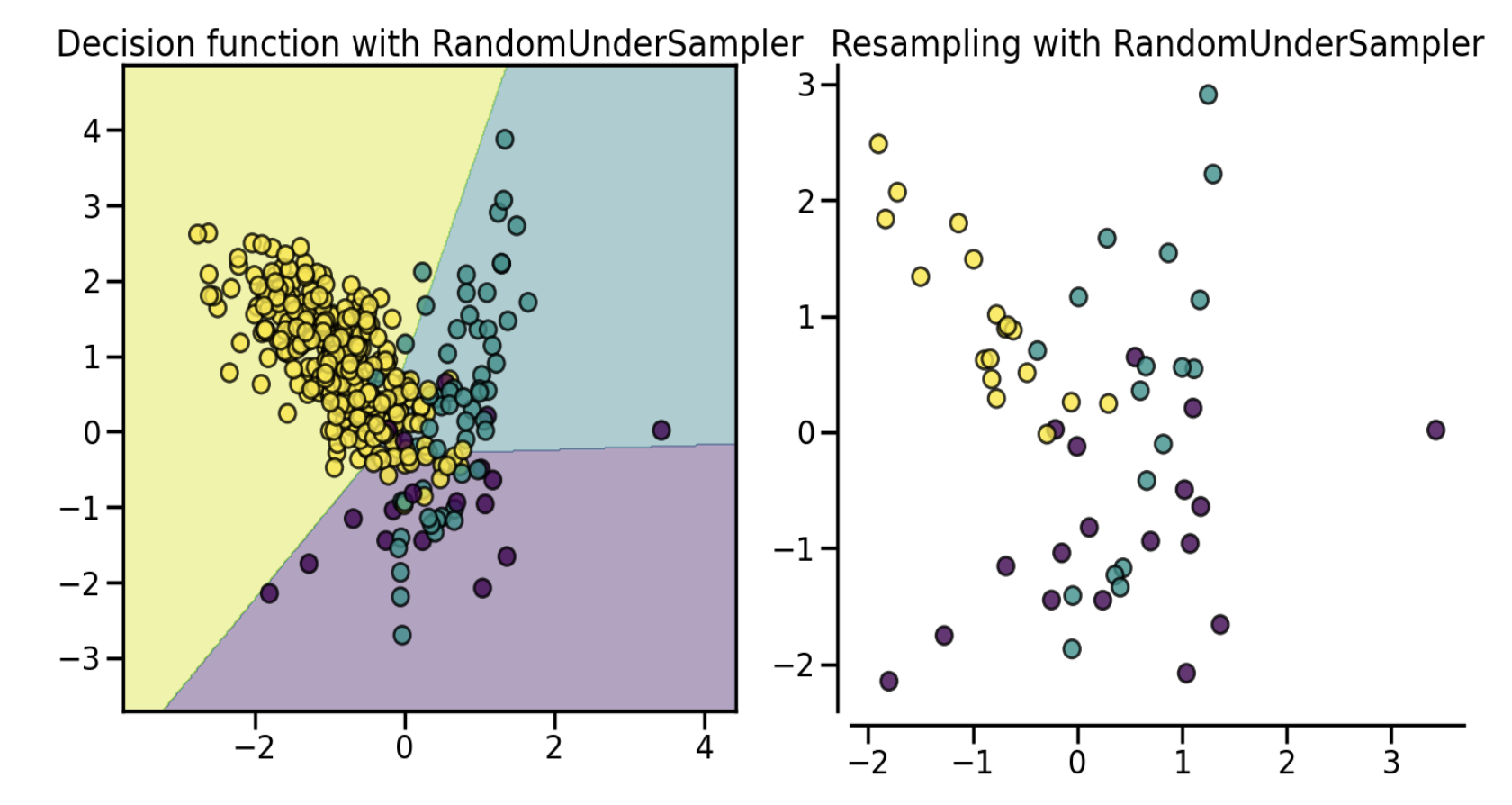
OverSampling Methods
The two representative oversampling methods are RandomOverSampling and SMOTE.
(1) RandomOverSampling It is a task of increasing the number of data by duplicating the data of the class with a low proportion to balance it. There is a problem that overfitting can occur for the minority class.
(2) SMOTE (Synthetic Minority Oversampling Technique) It is a technique that fills in virtual data around the existing minority class based on the KNN algorithm. One of the minority classes is randomly selected. It finds K minority class neighbors in that class, randomly selects one of them, and generates virtual data between the two selected classes.
When visualizing the differences between each oversampling technique, it looks like this. 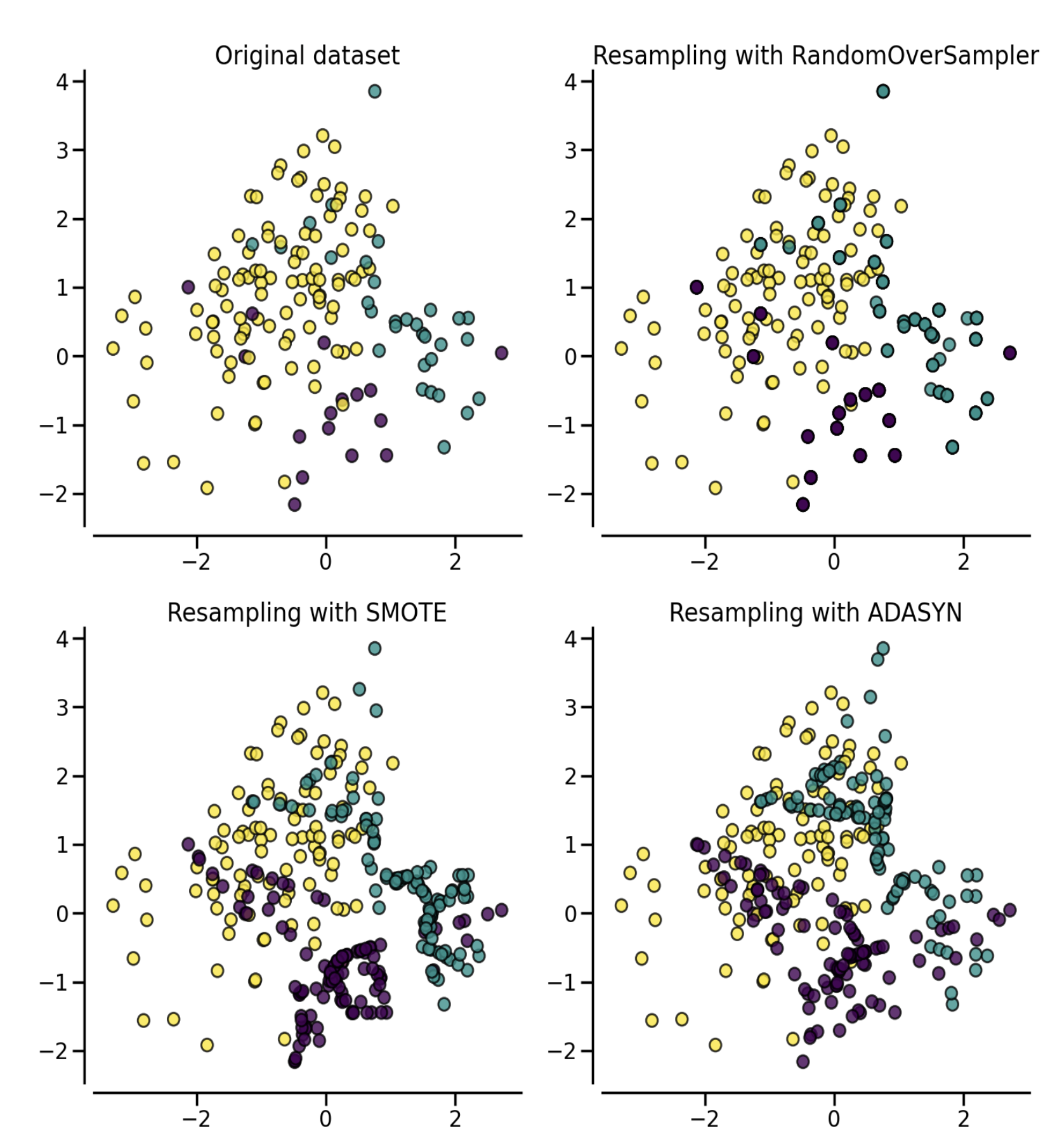
When there is little data, it is better to choose OverSampling rather than UnderSampling, and it seems reasonable to use each sampling method by directly comparing them as shown above.