
[DS]Data Preprocessing - How Does Normalization Affect Random Forest?
Published in , 2024
This time, we will look at how normalization affects the Random Forest technique. To understand this accurately, we need to understand the concepts of Random Forest and Normalization.
Concepts
Random Forest
Random Forest is a supervised learning algorithm that can perform both regression and classification tasks. 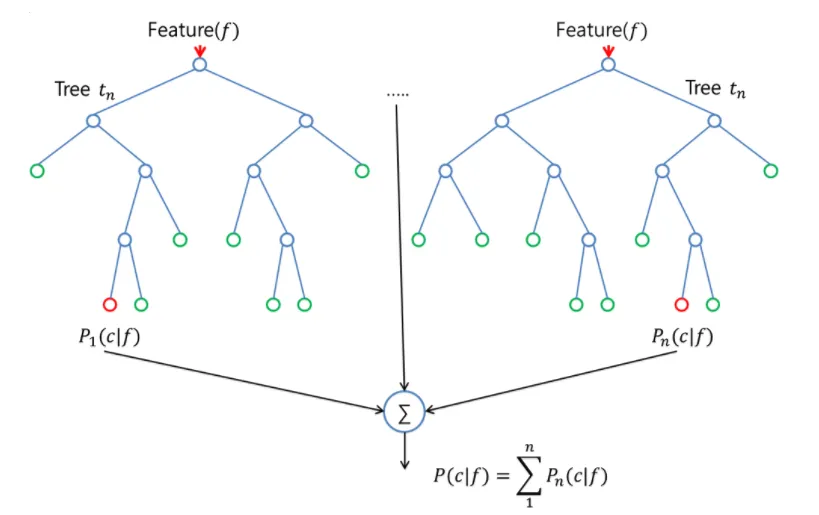
Source: https://www.analyticsvidhya.com/blog/2015/06/tuning-random-forest-model/
As shown in the figure above, Random Forest consists of multiple layers of decision trees.
The learning method of Random Forest is well illustrated in the figure below. 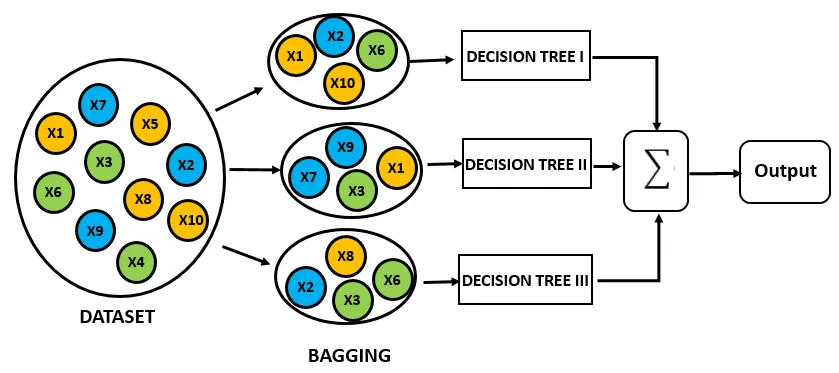
Source: https://www.analyticsvidhya.com/blog/2015/06/tuning-random-forest-model/
It uses a bootstrap method, which allows for the selection of random data with replacement. It also creates multiple decision trees and uses an ensemble method to utilize the predictions of many trees. Random Forest is composed of a set of decision trees with randomness using bootstrap, and it applies the ensemble method to various decision trees to produce multiple predictions, which are then combined into a final prediction through bagging.
Normalization
Normalization refers to the process of adjusting the scale of features to a certain range. This is used to prevent certain features from having an excessively large impact when the values of each feature have different scales in machine learning algorithms. There are four main normalization methods:
Log Transformation: When the distribution of data is asymmetric, log transformation can mitigate the distribution to make it closer to a normal distribution. It is useful for handling large values.
Min-max Normalization: This method transforms data into values between 0 and 1. It adjusts the scale by setting the minimum value of the data to 0 and the maximum value to 1.
Z-score Normalization: This method normalizes data by setting the mean to 0 and the standard deviation to 1. It indicates how far each data point is from the mean and is based on the standard normal distribution.
Decimal Scaling: This method normalizes data by adjusting the number of decimal places. It scales the values by dividing the data by a power of 10.
These normalization methods help improve the performance of algorithms and balance the data during the learning process.
The image below visualizes the log transformation process. ![]()
Source: https://www.pharmalex.com/thought-leadership/blogs/log-or-not-log-transform-data-thats-the-question/
Conclusion
Summarizing the two concepts above, you might intuitively feel that normalization is not necessary for Random Forest.
Why is it unnecessary to normalize data for the Random Forest algorithm?
The process of normalizing data is to ensure that no particular feature is prioritized over others. This technique is especially important in distance-based algorithms like K-Nearest Neighbors (KNN) or K-Means, which use Euclidean distance. However, the Random Forest algorithm is a tree-based model, not a distance-based model. Each node in Random Forest does not compare feature values but simply splits sorted lists for branching. Since this algorithm performs predictions by splitting data, normalization is not required.