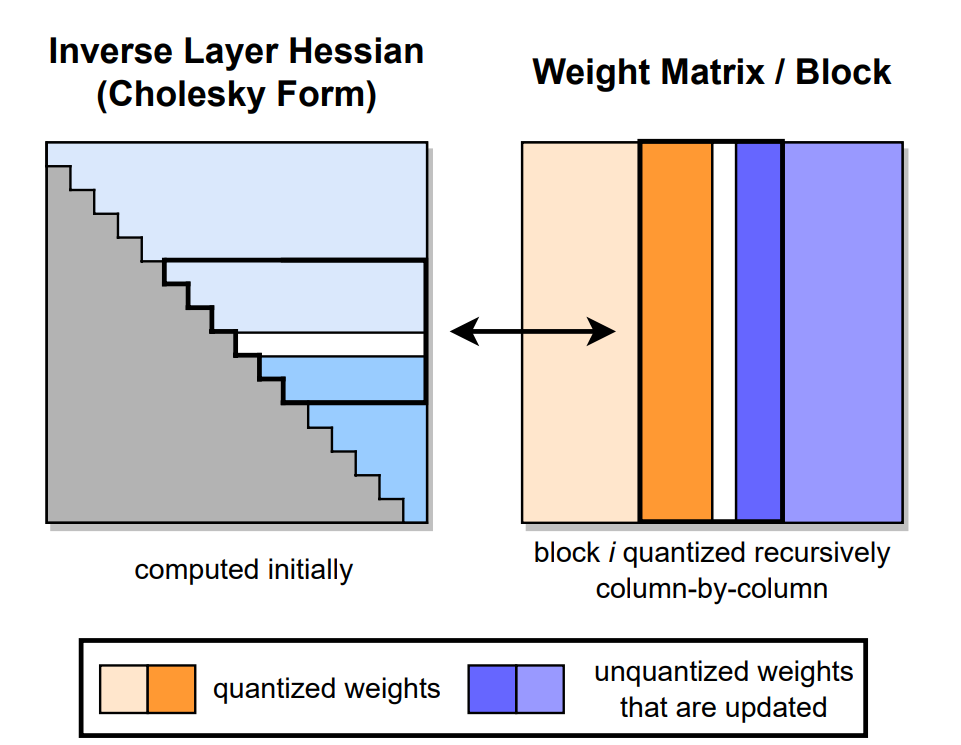
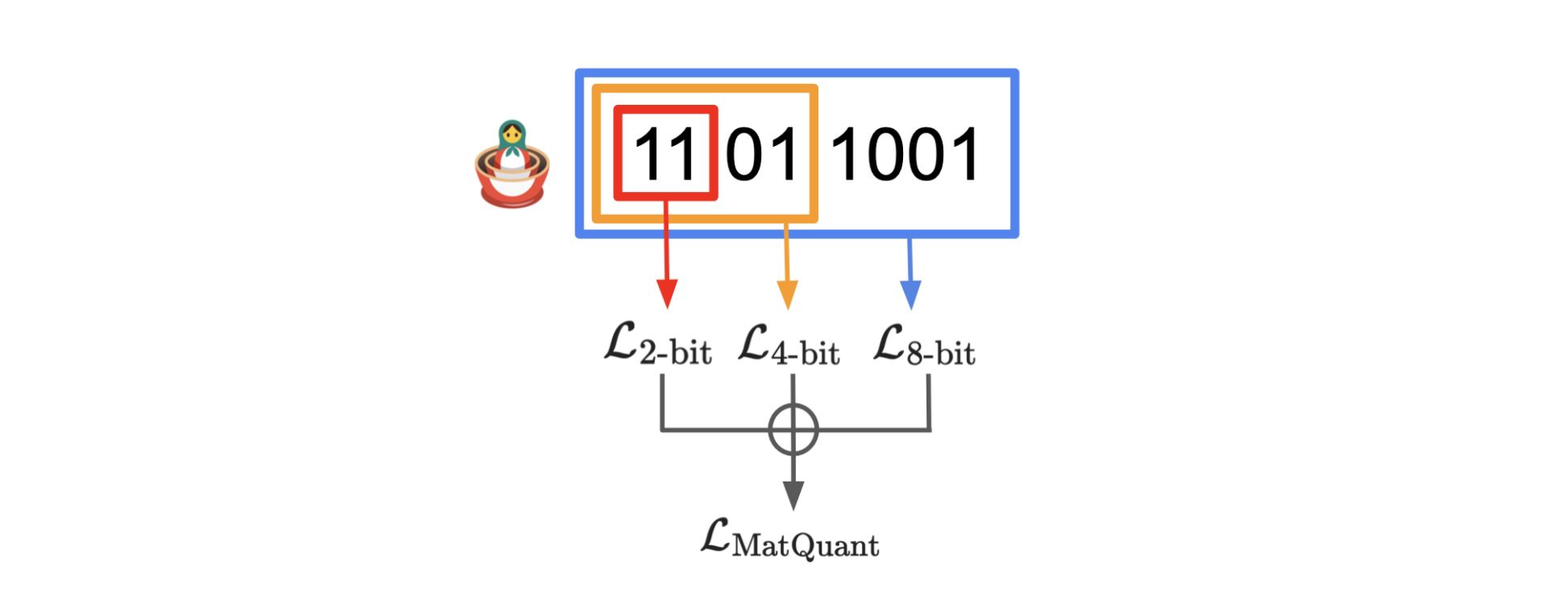
Matryoshka Quantization
Published in , 2025
In the era of massive language models and vision transformers, model efficiency has become just as important as accuracy. Whether you’re deploying on mobile, edge devices, or scaling inference infrastructure, quantization is a crucial technique for compressing models while maintaining performance.