[CUDA] CPU vs GPU with python
Published:
This column compares the speed of the CPU and GPU.

Published:
This column compares the speed of the CPU and GPU.
Published:
This time we will look at the basic concepts of UnderSampling and OverSampling.
Published:
This time, we will look at how normalization affects the Random Forest technique. To understand this accurately, we need to understand the concepts of Random Forest and Normalization.
Published:
Which should you choose between One-Hot Encoding and Label Encoding in Random Forest?
Published:
Let’s try to understand Bayesian optimization from the basic perspective of the Bayesian approach.
Published:
Published in , 2024
Published in , 2024
Published in , 2024
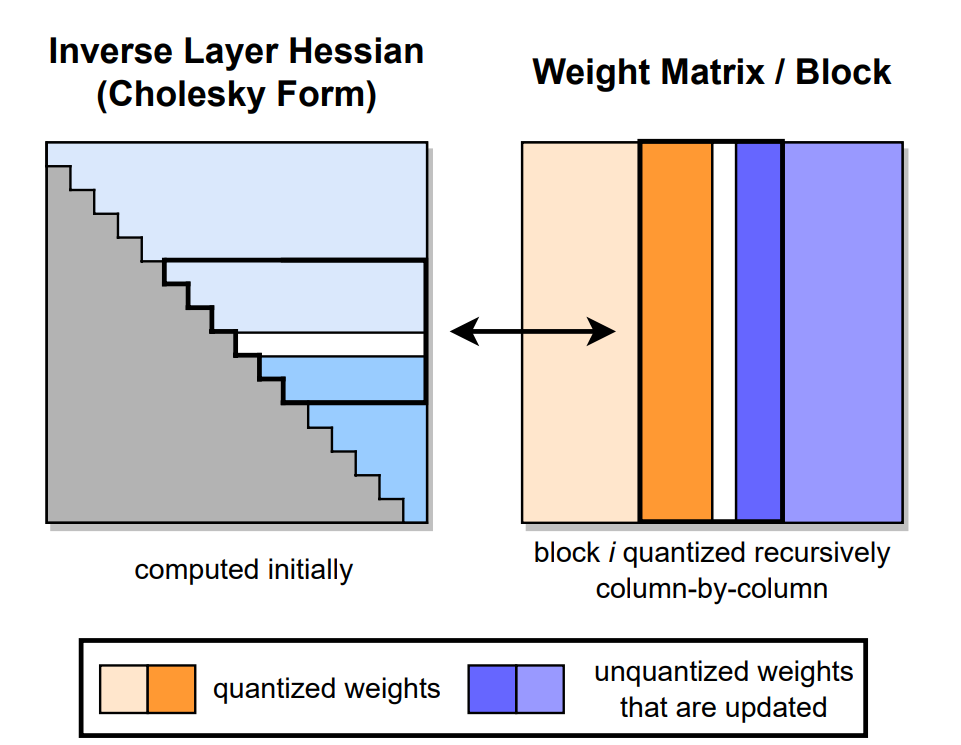
Summarization of GPTQ
Published in , 2024
Today, I will summarize the paper titled “FLEXTRON: Many-in-One Flexible Large Language Model.” The primary focus of this paper is to propose a novel framework with an elastic structure that can quickly adapt to diverse user environments. To achieve this, paper suggests that like Mixture-of-Experts.
Published in , 2025
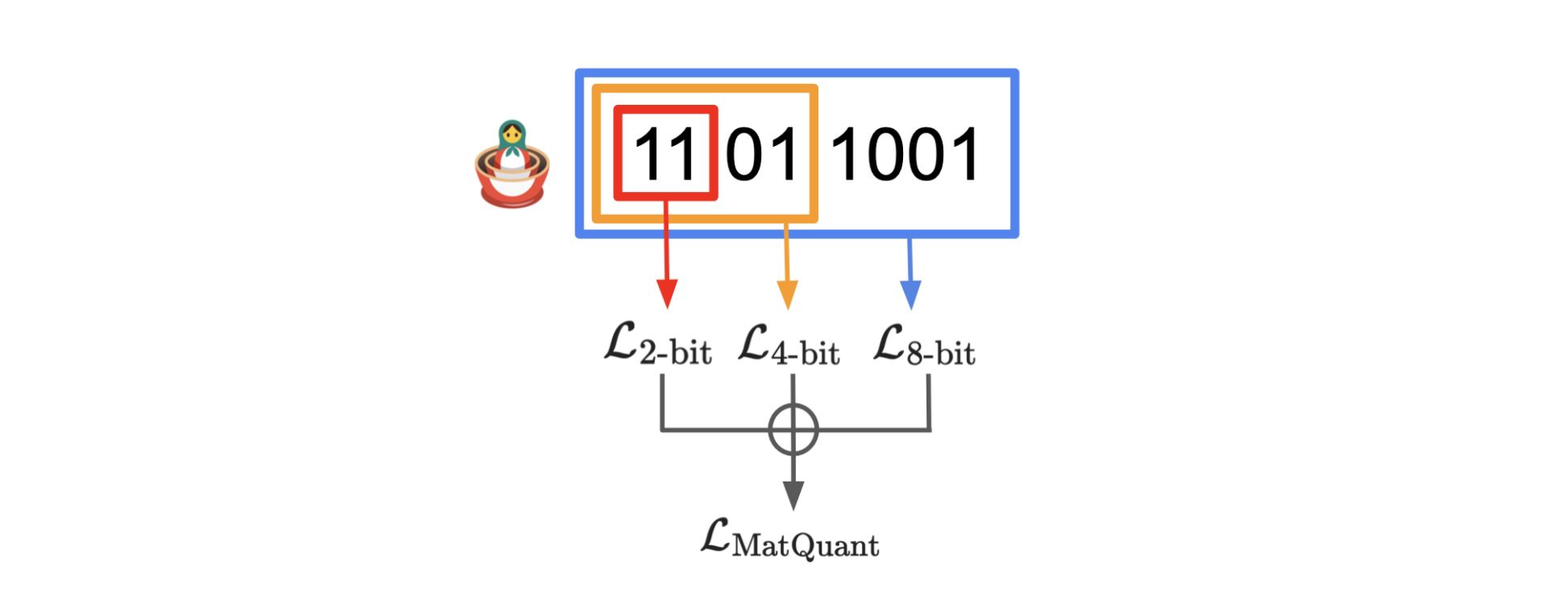
In the era of massive language models and vision transformers, model efficiency has become just as important as accuracy. Whether you’re deploying on mobile, edge devices, or scaling inference infrastructure, quantization is a crucial technique for compressing models while maintaining performance.
Published in ICCV 2025, 2025
* equal contribution, † corresponding author
Recommended citation: https://www.arxiv.org/pdf/2507.22349
Published:
정밀도 축소(Quantization) 및 효율적 추론 최적화에 대한 정리.
메모리 내 연산(Compute-in-Memory). 아직 공부 중인 분야.
<!DOCTYPE html>
<!DOCTYPE html>